How We Approach Node Monitoring
Table of contents (9)
- 11. Check Your Alerts and See if Action Is Required
- 22. Scan Your Logs to Identify Warnings and Errors before They Escalate
- 33. Review Your Pending Job Proposals to Actually Get Your Job Done
- 44. Make Sure Your Nodes Perform Their Tasks Correctly to Maximize Profits
- 55. Observe the Health of Your RPC Nodes to Get the Best Possible Performance
- 66. Take a Look At Your External Adapters and Ensure High Data Quality
- 77. Check Your Node Wallet Balance to Avoid Running out of Fuel
- 88. Examine Your System and Network Health to Maintain a Solid Foundation
- 9Systematizing the Monitoring Routine
Comprehensive monitoring of a Chainlink node environment is demanding and requires continuous dedication. With one less hurdle to overcome in creating and maintaining meaningful dashboards, you can devote more resources to optimizing the performance of your nodes and increase your chances of qualifying for new integrations.
In this article, we would like to share the results of our years of dedication to the Chainlink network and fine-tuning our monitoring system to provide structured coverage of all infrastructure components.
We believe that performing regular monitoring routines is crucial to prevent incidents and proactively manage the health and performance of your growing node environment. Such routine serves as a supporting measure for a well-configured alerting stack and, in the best case, helps to ensure that it has to notify you as little as possible.
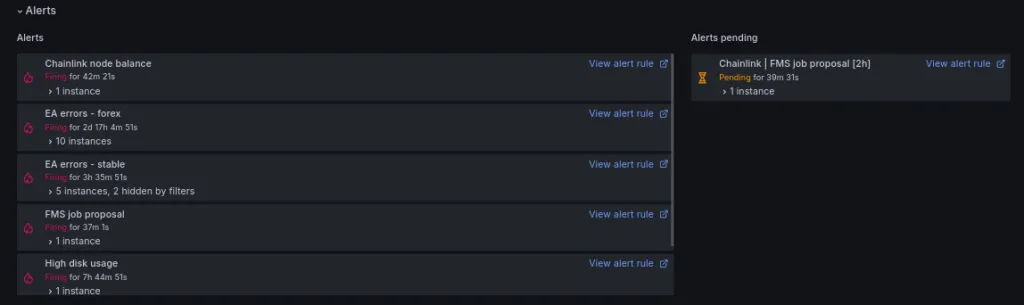
1. Check Your Alerts and See if Action Is Required
When you start your shift, the first thing you should do is check for any previous alerts that have not yet been resolved. This assumes that your alerting system is already set up properly. There are powerful tools to set up on-call schedules for teams and create an interactive, collaborative alerting experience.
In addition to the usual channels to which alerts are sent, a simple overview panel in the monitoring dashboard can quickly provide information about unresolved alerts. The most important thing is to have complete confidence that your alerts will only fire when necessary while covering all critical scenarios.
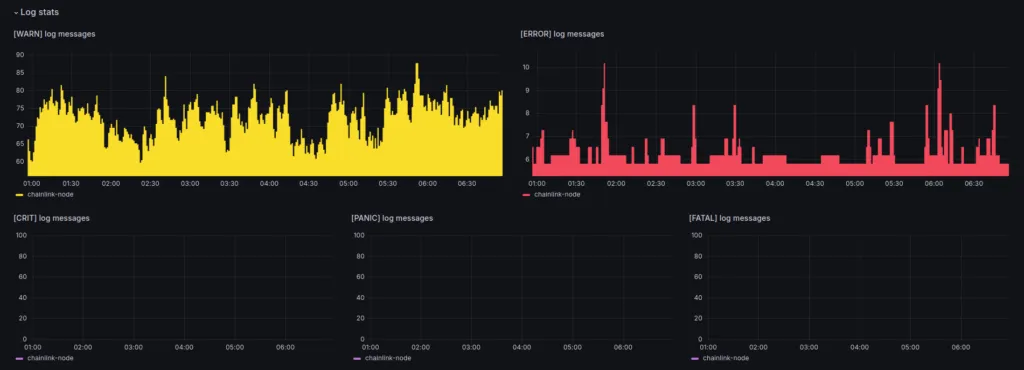
2. Scan Your Logs to Identify Warnings and Errors before They Escalate
Log monitoring plays an important role if you want to perform at the highest possible level. You don’t want to find out retrospectively that one of your nodes has been issuing [WARN], [ERROR] or even more serious log messages for days. Therefore, you should use panels that track the occurrence of log messages of the respective level and clearly visualize their volume.
A sudden spike or a persistent occurrence of log messages that go beyond the [INFO] level should definitely be checked. This means that an impending incident can be identified at a glance and avoided through proactive investigation.
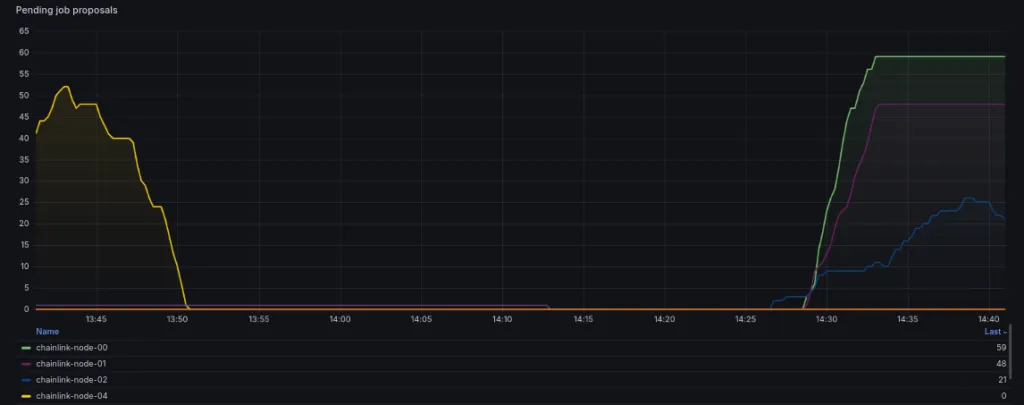
3. Review Your Pending Job Proposals to Actually Get Your Job Done
New jobs must be added to nodes regularly, existing ones are updated or canceled from time to time. The goal of a Chainlink node operator should be to complete these tasks in the shortest possible time. The reason for this is that the respective DON only benefits from a change when a sufficient number of nodes are running the latest version of a job.
Therefore, it is important to check all nodes for pending job proposals during a monitoring routine, which can be easily achieved using a dedicated panel.
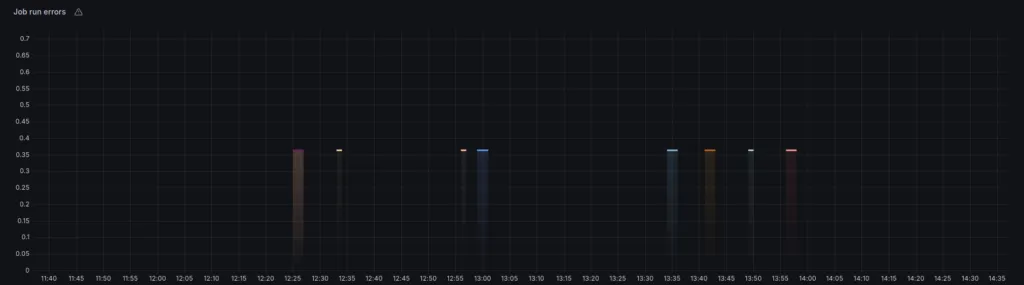
4. Make Sure Your Nodes Perform Their Tasks Correctly to Maximize Profits
The fourth step of the routine is to check the job run performance. This is crucial because a node’s performance in executing jobs directly impacts both its reputation and profitability.
There are several reasons that can lead to intermittent or dropped round observations, so special attention should be paid to them. Because of the impact job run performance has, we have even dedicated a whole article to the 4 OCR Job Run Metrics Every Chainlink Node Operator Should Monitor.
If you spot persistent job run errors during your routine, take immediate steps to identify and fix the underlying root cause. The number of round observations performed, as well as bridge errors and their latency should be clearly displayed in dedicated panels.
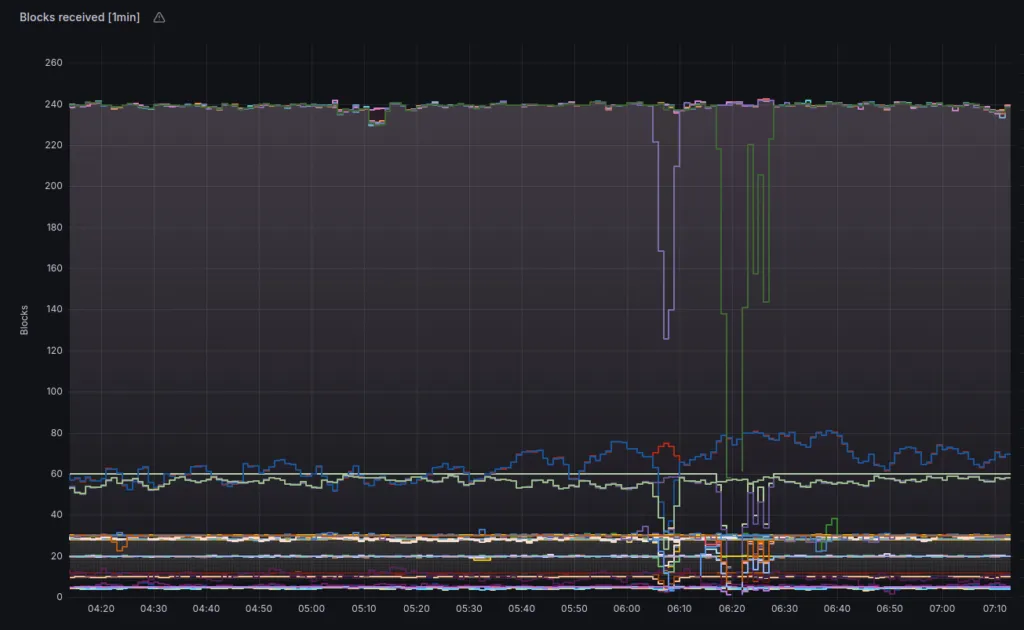
5. Observe the Health of Your RPC Nodes to Get the Best Possible Performance
An important key performance indicator for Chainlink nodes is their connection quality to the supported blockchain network. With the increasing number of networks supported by Chainlink, it is even more critical to monitor the health and functionality of all RPC nodes during your monitoring routine.
If an RPC node lags behind or is completely non-functional, the on-chain interaction of your node is impaired, which in turn affects reputation and profitability.
To identify problems, all you need to do is take a quick look at a clear panel that visualizes the block-per-minute trend of all full nodes in use. This will help you identify and resolve connection problems before they affect your Chainlink node’s performance.
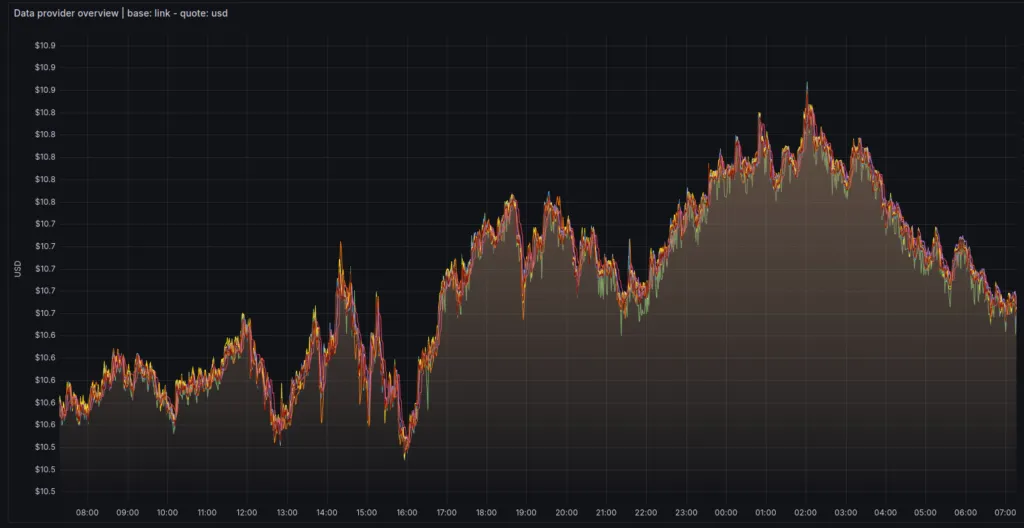
6. Take a Look At Your External Adapters and Ensure High Data Quality
In addition to checking all Chainlink node metrics during your daily monitoring routine, it is also important to keep an eye on the External Adapters. Clear displays of request response time and adapter errors quickly indicate whether an intervention is necessary.
The endpoints of the requested data providers can be a source of errors and should therefore be observed as well. This includes outlier response values compared to the current DON median, which can damage the reputation of your node.
A proactive check of data quality should therefore be an integral part of every monitoring routine.
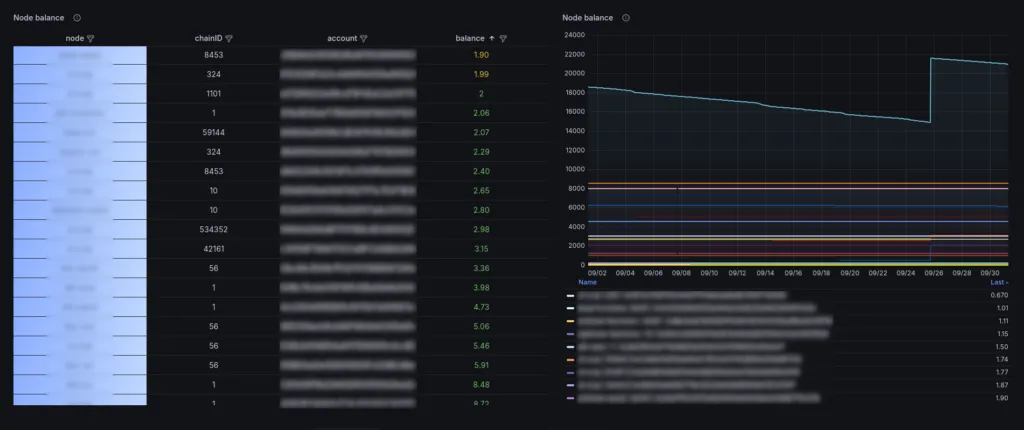
7. Check Your Node Wallet Balance to Avoid Running out of Fuel
As you know, the account balance of each node must never fall below a certain threshold in order to ensure successful on-chain transmissions in any situation. In addition to alerting on the respective thresholds, the balances should be checked proactively.
In this way, rising transaction costs and rapidly declining account balances can be identified early on and precautions can be taken before it becomes difficult or even impossible due to network congestion.
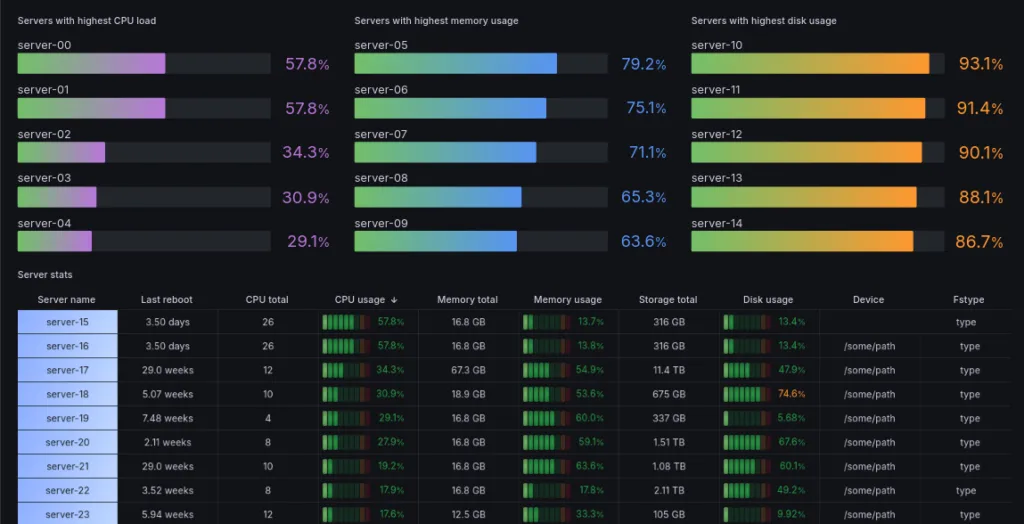
8. Examine Your System and Network Health to Maintain a Solid Foundation
The underlying host infrastructure is obviously the foundation on which every Chainlink node environment is built. To avoid irreversible damage and unwanted surprises, it is crucial to check basic system metrics as the last step of your daily monitoring routine.
Well-structured panels displaying the available disk space, as well as CPU and memory utilization of the hosts provide information about the health of your infrastructure.
Systematizing the Monitoring Routine
Running these checks by hand every day does not scale. Building meaningful Chainlink monitoring dashboards from scratch is difficult and time-consuming, and node operators have to track a wide range of shifting metrics and write the queries and panels behind them. As our footprint grew, we invested in turning this routine into standardized dashboards and alerting, so the signals above are captured continuously rather than depending on a manual daily pass. Codifying the routine once is what lets a small team operate reliably across many networks.